
As types of studies improve and adapt there’s an interesting extension to Maximum Difference Scaling (or more commonly MaxDiff analysis) that leverages the concept of Kano model. This extension opens up the use of MaxDiff to provide additional deeper insight into the results and additional guidance when activating the findings of a MaxDiff study. Before we get into the combination of MaxDiff and Kano analysis, let’s dive into both of them separately.
Maximum Difference Scaling (MaxDiff)
MaxDiff analysis is a common type of discrete choice analysis that is leveraged in product development, message/claims testing, shelf set optimization, etc. It involves asking a series of questions that places a handful of items (whether product features, claims, or potentially even entire product concepts themselves) and asks respondents to pick the best and worst options from among the items on the screen. Respondents go through several of these screens showing different subsets of items. This allows researchers to then look at the choices from the exercise and construct a preference model that not only ranks the items but shows the magnitude of difference between the preference of these items; the scores are presented on a continuous scale. A MaxDiff emphasizes differentiation between items, helping to identify winners and losers.
The Kano Model
The Kano theory is notable for questioning peoples’ inherent biases for thinking about the utility product features provided as linear. Better performance equals a proportionate increase in utility of the product, right? Well, this overlooks the possibility of diminishing returns or other types of nonlinear utility functions. Kano theory instead classifies product attributes into four different categories: performance attributes that are relatively linear in utility, delighter attributes which are not necessary in the product but help set it apart by providing an extra utility if they are included, must have attributes that are table stakes or expectations that are needed but whose utility has incredible diminishing returns, and indifferent attributes that not very important or offer much utility to consumers.
Now let’s apply these theories in real life.
When thinking about a car’s fuel economy, this characteristic might be considered a performance attribute, low gas milage is bad from a consumer perspective and high gas milage is considered good. This is how people traditionally think of product attributes; but now think of the car’s seat belts. In Kano theory these are traditionally thought of as must have attributes as no one is going to buy a car with no seat belts, it’s a basic necessity for cars, but very few people are paying close attention to seat belt specs to compare if car A or car B has better seat belts. Luxurious features such as assisted parking or a moonroof might be considered a delighter attribute, as it’s not needed to drive a car but is a helpful feature people might be interested in having and set your car apart from others.
Kano theory is a useful addition to leverage with a MaxDiff. A MaxDiff might tell you that an attribute is important or not, but it doesn’t tell you anything about how it’s important or the risk of neglecting it. Going back to the car example, imagine that you are asking respondents which product features motivate them to buy a car. The assisted parking and fuel economy might both rise to the top of a MaxDiff, but that is only part of the story. Both might motivate people to buy a car; however, the risk of neglecting them might not be the same. As a performance attribute, neglecting fuel economy is a much bigger risk than neglecting assisted parking if you can only focus on one or the other.
Likewise, must-have attributes might fly under the radar in a MaxDiff exercise. On a screen that puts fuel economy, assisted parking and seat belts against one another most people are probably going to flag seat belts as the least motivating feature for the purchase of a car compared to the other two. Respondents likely aren’t putting thought into the exact type of seat belt in the car; but, they will certainly notice if they are missing. Extending the MaxDiff exercise to incorporate Kano theory can provide this additional context and prevent car manufacturers from deciding that they can just forgo seat belts as “they aren’t important anyway.”
Now how exactly do we extend a MaxDiff exercise to incorporate Kano Theory into the story?
The answer is relatively simple. The MaxDiff exercise itself doesn’t change, we still present respondents with a series of screens where they select the best and worst options from a subset of items being tested.
After the MaxDiff, we ask a series of follow-up questions to better understand the attitude towards each feature in the framework of the Kano model. It could be a traditional Kano question asked both on inclusion and exclusion of each feature. But since the MaxDiff exercise can be lengthy, we often recommend using a shortened and simplified question, especially if we need to evaluate many features. An example of a simplified question for each feature tested in a MaxDiff is below:
If you consider the following features, how would you feel about it being included in the product being tested?
- I DISLIKE it, and would NOT buy product being tested if INCLUDED
- I DISLIKE it, but would still buy product being tested if INCLUDED
- I’m NEUTRAL, and would still buy product being tested if NOT INCLUDED
- I’m NEUTRAL, but would NOT buy product being tested if NOT INCLUDED
- I LIKE it, but would still buy product being tested if NOT INCLUDED
- I’m EXCITED about it, and would NOT buy product being tested if NOT INCLUDED
Often times, we recommend an additional extension by asking a question to anchor the MaxDiff in an integrated MaxDiff-Kano analysis. An Anchored MaxDiff has the same advantages as a standard approach – it provides the scores on a continuous scale and enhances differentiation between items. It also puts the scores on an absolute scale: all the attributes with the scores higher than the anchor are important or interesting to customers, and attributes with scores lower than the anchor are not important or interesting.
From this simple series of questions, we can now draw out how delighting the product feature is and then combine that with the importance/consideration derived from the MaxDiff analysis to not only rank the attributes but also to classify the attributes according to Kano Theory. Staying with our car example, very few respondents will consider the inclusion of a seat belt as a motivating factor in their purchase decision, but we can expect that most respondents are going to select option 4 in the scale above and indicate that they wouldn’t purchase the item flat out if it is not included. And with that additional dimension we now have a slightly different story and interpretation (particularly for the seat belts) of the results that a MaxDiff alone can’t provide.
When all is said and done, we can take the data and generate a visualization of the results that is easy to read.
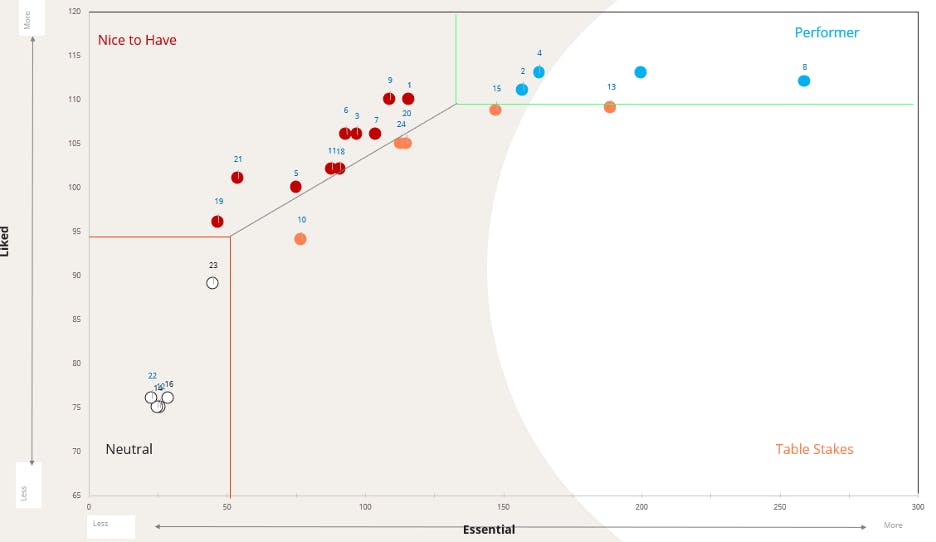
Extending a MaxDiff to include a Kano analysis is a relatively simple and easy way to add a new dimension to your research, look at the data on a deeper level, and find additional insights that you might miss by only conducting a MaxDiff exercise on its own. Big Village looks forward to discussing your product development needs and how a fusion of a MaxDiff and Kano analysis can provide new insight into your business and take your marketing research to the next level.
Written by Tyler Dugan, Senior Data Analyst.